
SGX
SGX is an award winning, production tested, automatic speech-to-facial animation system.
Over 20 years of R&D in speech technology, linguistics, machine learning and procedural facial dynamics are at the core of SGX. Through the innovative application of acoustic analysis and muscle dynamics, SGX produces accurate, consistent, natural lip sync and remarkable full-face emotional expression from just audio and optional text.
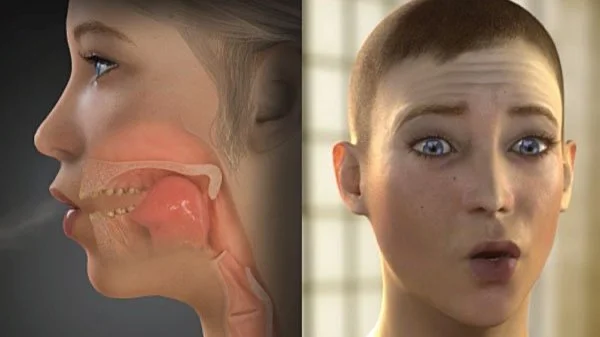
Quality.
Anatomically correct. Speech is analyzed and translated into virtual muscle activations within our vocal tract simulation.
This can be adapted for diverse physiologies to drive animals, aliens, monsters and more, across the spectrum from cartoons to stylized characters, to hyper-realistic virtual humans.

Speed & Efficiency.
Fully automated facial animation from audio. Optional use of transcripts supports disambiguation and mark-up to maximise accuracy and control.
Highly flexible; works with almost any rig. Specific plugins for Maya and Unreal help you realise your creative vision faster than ever.
Easy to control. The SGX Director module facilitates in-situ adjustments via a timeline editor and re-processing, without the need to work at the keyframe level.

Emotional. Intelligent. Accurate.
Define the desired mood and intensity to realize the emotional nuance you envision. With the included SGX Studio Maya plugin you can create an unlimited library of built-in and custom Behavior Modes that are exactly right for your characters and dialog.
Mode library – Author and choose from an unlimited number of Behavior Modes with an unlimited number of facial expressions for a given mode
Bi-Tonal Modes – These special modes modulate facial expressions based on changes in the pitch and intensity of audio
Markup – Set the Behavior Modes of a performance across a batch of lines, for an individual line, or multiple times within a single line of dialog
Automatic Mode Detection – Automatically select Behavior Modes for a vocal performance through automatic emotion detection (positive, negative and neutral) and voice mode detection (e.g. effort) technology.