
Representing Emotions Using Large Language Models
Interspeech 2023
Last year, the Speech Graphics Research team had a trip to Ireland for INTERSPEECH, the world’s largest and most comprehensive conference on the science and technology of spoken language processing. It is a hugely important event for our research community and the team were honoured to contribute.
Head of Machine Learning, Dr Dimitri Palaz was thrilled to take home the prestigious “ISCA Award for Best Paper Published in Speech Communication (2018-2022),” and Research Engineer Eimear Stanley presented a paper written by the Speech Graphics team. In the blog below, Dimitri and Eimear introduce the paper they presented - “Emotion Label Encoding using Word Embeddings for Speech Emotion Recognition.”

L to R: Dr Dimitri Palaz, Samuel Lo, Michael Berger, Georgia Clarke, Eimear Stanley, Anita Klementiev
Paper Summary
Dr Dimitri Palaz, Head of Machine Learning
Eimear Stanley, Research Engineer
The goal of Speech Graphics audio-driven facial animation technology is to provide accurate and believable facial animation driven by speech only. To achieve that, our technology produces very accurate lip sync, but that's not all. We also animate the whole face, including head motion, blinks, and most importantly facial expressions. These expressions should reflect the emotional state of the speaker, to be as believable as possible - for example, when the voice sounds angry the character should look angry. Therefore, selecting the most appropriate expression implies detecting the emotion in the voice as accurately as possible. This task of classifying emotion from audio is referred to as Speech Emotion Recognition (SER) in the literature, and it’s known to be quite challenging. In this paper, we present an approach to improving SER systems, where we investigate a novel avenue of research on obtaining a better representation of emotion leveraging Large Language Models (LLMs).

Representing Emotions
Human emotion is complex and can be difficult to represent. You may be familiar with images such as the “feelings wheel”, which is used as a tool to help people identify their own emotions. Starting with broad labels, you work your way towards the outside of the circle to try and find an appropriate label to represent how you are feeling. This can be challenging, as you can experience more than one emotion at a time and a single label may not accurately represent how you feel.

Given it can be a difficult task to identify our own emotions, it is no surprise that a core challenge faced by speech emotion recognition is having adequate representations of emotions that a model can learn from. There are two common ways of representing emotion in machine learning: the categorical approach, and the continuous approach.
The categorical approach uses a small subset of emotion labels. Each utterance in a dataset is then assigned just one of these labels. This can be equated to only using the innermost circle of the feelings wheel, which cannot account for complex and nuanced emotions.

The continuous approach attempts to represent emotion in terms of attributes, such as arousal, valence and dominance. While representing emotion in a multi-dimensional space allows for more fine-grained labels, this adds complexity to the already difficult task of annotating emotion.

This prompts the question, can we get better representations of emotion?
In our paper, we propose using Large Language Models (LLMs) to get alternative representations of emotion. As we will explain in the following section, LLMs can represent words in a way that captures the context and meaning of words. Additionally, they are trained on huge amounts of data without the need for someone to manually label that data. These two points mean we can get representations of emotion that capture the nuance of emotion without a complicated manual labelling approach.
Using Large Language Models
Large Language Models (LLMs) are neural network based models that use extremely large amounts of data to learn about language. Some popular LLMs include word2vec, GloVE and GPT - used in the popular application ChatGPT. These models can be used to get representations for a given word, called a word embedding. A word embedding is a series of numbers that represents a word in high-dimensional space. Word embeddings are learnt representations that preserve relationships of meaning and sentence position between the words. This means words that have similar meaning, have similar word embeddings.
Below is an illustration of a word embedding. Each circle is a dimension of the vector that contains a number value, together these dimensions encode information about the word. As you can see, word embeddings are made up of a large amount of dimensions, often ranging from 100s to 1000s.

A useful property of word embeddings is the ability to perform simple arithmetical operations on them. To explain this, let’s imagine we want to find the word embedding for Rome. We can start from known embeddings - the embeddings for Paris, France and Italy - and use subtraction and addition in the following way:
Rome = Paris - France + Italy
(example taken from https://arxiv.org/pdf/1301.3781.pdf)
Our Approach
In our paper, we present a novel approach to represent emotions for SER, that leverages the information contained in word embeddings. Instead of using categorical labels to train our SER model, we use the word embedding for the emotion label.
Additionally, we proposed using geometry to combine emotion labels. For example, if we have a datapoint that has been labelled by three annotators with the labels {“happy”, “happy”, “excited”}, we first get the word embedding for each individual label, sum them together and then take the average. This results in a vector on the line between the word embeddings for “happy” and “excited”, a third of the distance from happy and two thirds from excited. Doing this allows us to capture the natural subjectivity of emotion as well as modelling entangled emotions. An additional benefit of this approach is that any emotion label can be included; annotators would not need to be confined to a small list of emotion labels to choose from. It is these emotion embeddings that we can use as labels when training our speech emotion recognition models.

Results
To compare our proposed approach with the standard categorical approach, we experimented with a well known dataset - IEMOCAP. In this dataset, multiple annotators label each utterance. To get ground-truth labels, majority voting is used to select the most common label given by the annotators.
Our first experiment used a subset of the ground truth labels. We got the word embedding for each label and used that to train our model. The model predicted vector embeddings, and using cosine similarity, we mapped the predictions back to the closest label in the subset. From the chart below, we can clearly see that our proposed approach, using word embeddings to represent emotion, helps the model to more accurately predict the correct emotion.

A key benefit of our approach is the ability to include multiple emotion labels in one representation, which improves the performance of the model. To illustrate this, we trained two models - one trained using the word embeddings of the ground-truth labels (M1), and a second model where we combined all the individual annotations into a single embedding (M2). Then we looked at the closest word embeddings to the predictions made by the two models on the same subset of data, namely the utterances from our test set that have “happiness” as their ground-truth label. The top 5 nearest neighbours for each model’s predictions can be seen in the illustration below. For M1 (trained on the ground-truth embeddings), the nearest neighbours don’t all correlate with “happiness” - most noticeably, “sadness” is included. Now looking at M2 (trained on combined label embeddings), the nearest neighbours to the model's predictions are all much more related to the meaning of “happiness”.
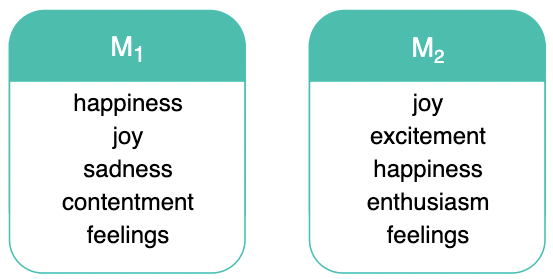
These results indicate that the model trained on combined label representations learns a more informed and nuanced representation of emotion.
To summarise, in our paper we proposed a novel approach of using word embeddings as labels for speech emotion recognition. We showed that this approach results in better performance than using categorical labels. A key benefit of our approach is being able to include multiple emotion labels in one combined embedding, which allows us to represent complex and entangled emotions. Additionally, using word embeddings allows us to use any emotion label. Future annotation schemes would not be limited to a small subset of emotions to choose from, but annotators could freely label utterances. This would result in more accurate labels that our models can learn from. It could also enable easier cross-corpus training where the label sets do not match, without the need to edit the labels. This is not possible in the standard categorical approach.
Conclusion
This research is really promising, clearly indicating that LLMs can be useful at representing complex concepts like emotion. While this research is going to improve Speech Graphics audio-driven facial animation technology, it also brings a novel and intriguing property: the set of emotions that the detection system can output is open-ended. This is unique as all machine learning systems normally have a fixed set of outputs (e.g. angry, happy, neutral, sad). Instead, in our approach the output of the system is actually a point in the LLM space, and the emotion is then selected by proximity, so any set of emotion words could in theory be selected with the same system (for example nostalgic, annoyed, distressed). From a product perspective, that paves the way for our users to be able to write their own emotion set as opposed to selecting them from a fixed, drop-down list. While this is very theoretical and needs more investigation, this shows the strong potential of this research.
For further detail and the full results of this research, our paper is available here.